3 Maximum likelihood estimation
3.1 Principle of maximum likelihood estimation
3.1.1 Outline
The starting points in an ML analysis are
- the observed data \(D = \{x_1,\ldots,x_n\}\) with \(n\) independent and identically distributed (iid) samples, with the ordering irrelevant, and a
- model \(F_{\boldsymbol \theta}\) with corresponding probability density or probability mass function \(f(x|\boldsymbol \theta)\) with parameters \(\boldsymbol \theta\)
From this we construct the likelihood function:
- \(L_n(\boldsymbol \theta|D)=\prod_{i=1}^{n} f(x_i|\boldsymbol \theta)\)
Historically, the likelihood is also often interpreted as the probability of the data given the model. However, this is not strictly correct. First, this interpretation only applies to discrete random variables. Second, since the samples are iid even in this case one would still need to add a factor accounting for the multiplicity of possible orderings of the samples to obtain the correct probability of the data. Third, the interpretation of likelihood as probability of the data completely breaks down for continuous random variables because then \(f(x |\boldsymbol \theta)\) is a density, not a probability.
As we have seen in the previous chapter the origin of the likelihood function lies in its connection to relative entropy. Specifically, the log-likelihood function
- \(l_n(\boldsymbol \theta|D)=\sum_{i=1}^n \log f(x_i|\boldsymbol \theta)\)
divided by sample size \(n\) is a large sample approximation of the cross-entropy between the unknown true data generating model and the approximating model \(F_{\boldsymbol \theta}\). Note that the log-likelihood is additive over the samples \(x_i\).
The maximum likelihood point estimate \(\hat{\boldsymbol \theta}^{ML}\) is then given by maximising the (log)-likelihood
\[\hat{\boldsymbol \theta}^{ML} = \text{arg max}\, l_n(\boldsymbol \theta|D)\]
Thus, finding the MLE is an optimisation problem that in practise is most often solved numerically on the computer, using approaches such as gradient ascent (or for negative log-likelihood gradient descent) and related algorithms. Depending on the complexity of the likelihood function finding the maximum can be very difficult.
3.1.2 Obtaining MLEs for a regular model
In regular situations, i.e. when
- the log-likelihood function is twice differentiable with regard to the parameters,
- the maximum (peak) of the likelihood function lies inside the parameter space and not at a boundary,
- the parameters of the model are all identifiable (in particular the model is not overparameterised), and
- the second derivative of the log-likelihood at the maximum is negative and not zero (for more than one parameter: the Hessian matrix at the maximum is negative definite and not singular)
then in order to maximise \(l_n(\boldsymbol \theta|D)\) one may use the score function \(\boldsymbol S(\boldsymbol \theta)\) which is the first derivative of the log-likelihood function:
\[\begin{align*} \begin{array}{cc} S_n(\theta) = \frac{d l_n(\theta|D)}{d \theta}\\ \\ \\ \boldsymbol S_n(\boldsymbol \theta)=\nabla l_n(\boldsymbol \theta|D)\\ \\ \end{array} \begin{array}{ll} \text{scalar parameter $\theta$: first derivative}\\ \text{of log-likelihood function}\\ \\ \text{gradient if } \boldsymbol \theta\text{ is a vector}\\ \text{(i.e. if there's more than one parameter)}\\ \end{array} \end{align*}\]
A necessary (but not sufficient) condition for the MLE is that \[ \boldsymbol S_n(\hat{\boldsymbol \theta}_{ML}) = 0 \]
To demonstrate that the log-likelihood function actually achieves a maximum at \(\hat{\boldsymbol \theta}_{ML}\) the curvature at the MLE must negative, i.e. that the log-likelihood must be locally concave at the MLE.
In the case of a single parameter (scalar \(\theta\)) this requires to check that the second derivative of the log-likelihood function is negative: \[ \frac{d^2 l_n(\hat{\theta}_{ML}| D)}{d \theta^2} <0 \] In the case of a parameter vector (multivariate \(\boldsymbol \theta\)) you need to compute the Hessian matrix (matrix of second order derivatives) at the MLE: \[ \nabla \nabla^T l_n(\hat{\boldsymbol \theta}_{ML}| D) \] and then verify that this matrix is negative definite (i.e. all its eigenvalues must be negative).
As we will see later the second order derivatives of the log-likelihood function also play an important role for assessing the uncertainty of the MLE.
3.1.3 Invariance property of the maximum likelihood
The invariance principle states that the maximum likelihood is invariant against reparameterisation.
Assume we transform a parameter \(\theta\) into another parameter \(\omega\) using some invertible function \(g()\) so that \(\omega= g(\theta)\). Then the maximum likelihood estimate \(\hat{\omega}_{ML}\) of the new parameter \(\omega\) is simply the transformation of the maximum likelihood estimate \(\hat{\theta}_{ML}\) of the original parameter \(\theta\) with \(\hat{\omega}_{ML}= g( \hat{\theta}_{ML})\). The achieved maximum likelihood is the same in both cases.
The reason why this works is that maximisation is a procedure that is invariant against transformations of the argument of the function that is maximised. Consider a function \(h(x)\) with a maximum at \(x_{\max} = \text{arg max } h(x)\). Now we relabel the argument using \(y = g(x)\) where \(g\) is an invertible function. Then the function in terms of \(y\) is \(h( g^{-1}(y))\). and clearly this function has a maximum at \(y_{\max} = g(x_{\max})\) since \(h(g^{-1}(y_{\max} ) ) = h( x_{\max} )\).
The invariance property can be very useful in practise because it is often easier (and sometimes numerically more stable) to maximise the likelihood for a different set of parameters.
See Worksheet L1 for an example application of the invariance principle.
3.1.4 Consistency of maximum likelihood estimates
One important property of maximum likelihood is that it produces consistent estimates.
Specifically, if the true underlying model \(F_{\text{true}}\) with parameter \(\boldsymbol \theta_{\text{true}}\) is contained in the set of specified candidates models \(F_{\boldsymbol \theta}\) \[\underbrace{F_{\text{true}}}_{\text{true model}} \subset \underbrace{F_{\boldsymbol \theta}}_{\text{specified models}}\] then \[\hat{\boldsymbol \theta}_{ML} \overset{\text{large }n}{\longrightarrow} \boldsymbol \theta_{\text{true}}\]
This is a consequence of \(D_{\text{KL}}(F_{\text{true}},F_{\boldsymbol \theta})\rightarrow 0\) for \(F_{\boldsymbol \theta} \rightarrow F_{\text{true}}\), and that maximisation of the likelihood function is for large \(n\) equivalent to minimising the relative entropy.
Thus given sufficient data the MLE will converge to the true value. As a consequence, MLEs are asympotically unbiased. As we will see in the examples they can still be biased in finite samples.
Note that even if the candidate model \(F_{\boldsymbol \theta}\) is misspecified (i.e. it does not contain the actual true model) the MLE is still optimal in the sense in that it will find the closest possible model.
It is possible to find inconsistent MLEs, but this occurs only in situations where the dimension of the model / number of parameters increases with sample size, or when the MLE is at a boundary or when there are singularities in the likelihood function.
3.2 Maximum likelihood estimation in practise
3.2.1 Likelihood estimation for a single parameter
In the following we illustrate likelihood estimation for models with a single parameter. In this case the score function and the second derivative of the log-likelihood are all scalar-valued like the log-likelihood function itself.
Example 3.1 Estimation of a proportion – maximum likelihood for the Bernoulli model:
We aim to estimate the true proportion \(\theta\) in a Bernoulli experiment with binary outcomes, say the proportion of “successes” vs. “failures” or of “heads” vs. “tails” in a coin tossing experiment.
- Bernoulli model \(\text{Ber}(\theta)\): \(\text{Pr}(\text{"success"}) = \theta\) and \(\text{Pr}(\text{"failure"}) = 1-\theta\).
- The “success” is indicated by outcome \(x=1\) and the “failure” by \(x=0\).
- We conduct \(n\) trials and record \(n_1\) successes and \(n-n_1\) failures.
- Parameter: \(\theta\) probability of “success”.
What is the MLE of \(\theta\)?
the observations \(D=\{x_1, \ldots, x_n\}\) take on values 0 or 1.
the average of the data points is \(\bar{x} = \frac{1}{n} \sum_{i=1}^n x_i = \frac{n_1}{n}\).
the probability mass function (PMF) of the Bernoulli distribution \(\text{Ber}(\theta)\) is: \[ p(x| \theta) = \theta^x (1-\theta)^{1-x} = \begin{cases} \theta & \text{if $x=1$ }\\ 1-\theta & \text{if $x=0$} \\ \end{cases} \]
log-PMF: \[ \log p(x| \theta) = x \log(\theta) + (1-x) \log(1 - \theta) \]
log-likelihood function: \[ \begin{split} l_n(\theta| D) & = \sum_{i=1}^n \log f(x_i| \theta) \\ & = n_1 \log \theta + (n-n_1) \log(1-\theta) \\ & = n \left( \bar{x} \log \theta + (1-\bar{x}) \log(1-\theta) \right) \\ \end{split} \] Note how the log-likelihood depends on the data only through \(\bar{x}\)! This is an example of a sufficient statistic for the parameter \(\theta\) (in fact it is also a minimally sufficient statistic). This will be discussed in more detail later.
Score function: \[ S_n(\theta)= \frac{dl_n(\theta| D)}{d\theta}= n \left( \frac{\bar{x}}{\theta}-\frac{1-\bar{x}}{1-\theta} \right) \]
-
Maximum likelihood estimate: Setting \(S_n(\hat{\theta}_{ML})=0\) yields as solution \[ \hat{\theta}_{ML} = \bar{x} = \frac{n_1}{n} \]
With \(\frac{dS_n(\theta)}{d\theta} = -n \left( \frac{\bar{x}}{\theta^2} + \frac{1-\bar{x}}{(1-\theta)^2} \right) <0\) the optimum corresponds indeed to the maximum of the (log-)likelihood function as this is negative for \(\hat{\theta}_{ML}\) (and indeed for any \(\theta\)).
The maximum likelihood estimator of \(\theta\) is therefore identical to the frequency of the successes among all observations.
Note that to analyse the coin tossing experiment and to estimate \(\theta\) we may equally well use the binomial distribution \(\text{Bin}(n, \theta)\) as model for the number of successes. This results in the same MLE for \(\theta\) but the likelihood function based on the binomial PMF includes the binomial coefficient. However, as it does not depend on \(\theta\) it disappears in the score function and has no influence in the derivation of the MLE.
Example 3.2 Normal distribution with unknown mean and known variance:
- \(x \sim N(\mu,\sigma^2)\) with \(\text{E}(x)=\mu\) and \(\text{Var}(x) = \sigma^2\)
- the parameter to be estimated is \(\mu\) whereas \(\sigma^2\) is known.
What’s the MLE of the parameter \(\mu\)?
the data \(D= \{x_1, \ldots, x_n\}\) are all real in the range \(x_i \in [-\infty, \infty]\).
the average \(\bar{x} = \frac{1}{n} \sum_{i=1}^n x_i\) is real as well.
Density: \[ f(x| \mu)= \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)\]
Log-Density: \[\log f(x| \mu) =-\frac{1}{2} \log(2\pi\sigma^2) - \frac{(x-\mu)^2}{2\sigma^2}\]
Log-likelihood function: \[ \begin{split} l_n(\mu| D) &= \sum_{i=1}^n \log f(x_i| \mu)\\ &=-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2 \underbrace{-\frac{n}{2}\log(2 \pi \sigma^2) }_{\text{constant term, does not depend on } \mu \text{, can be removed}}\\ &=-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i^2 - 2 x_i \mu+\mu^2) + C\\ &=\frac{n}{\sigma^2} ( \bar{x} \mu - \frac{1}{2}\mu^2) \underbrace{ - \frac{1}{2\sigma^2}\sum_{i=1}^n x_i^2 }_{\text{another constant term}} + C\\ \end{split} \] Note how the non-constant terms of the log-likelihood depend on the data only through \(\bar{x}\)!
Score function: \[ S_n(\mu) = \frac{n}{\sigma^2} ( \bar{x}- \mu) \]
Maximum likelihood estimate: \[S_n(\hat{\mu}_{ML})=0 \Rightarrow \hat{\mu}_{ML} = \bar{x}\]
With \(\frac{dS_n(\mu)}{d\mu} = -\frac{n}{\sigma^2}<0\) the optimum is indeed the maximum
The constant term \(C\) in the log-likelihood function collects all terms that do not depend on the parameter. After taking the first derivative with regard to the parameter this term disappears thus \(C\) is not relevant for finding the MLE of the parameter. In the future we will often omit such constant terms from the log-likelihood function without further mention.
Example 3.3 Normal distribution with known mean and unknown variance:
- \(x \sim N(\mu,\sigma^2)\) with \(\text{E}(x)=\mu\) and \(\text{Var}(x) = \sigma^2\)
- \(\sigma^2\) needs to be estimated whereas the mean \(\mu\) is known
What’s the MLE of \(\sigma^2\)?
the data \(D= \{x_1, \ldots, x_n\}\) are all real in the range \(x_i \in [-\infty, \infty]\).
the average of the squared centred data \(\overline{(x-\mu)^2} = \frac{1}{n} \sum_{i=1}^n (x_i-\mu)^2 \geq 0\) is non-negative.
Density: \[ f(x| \sigma^2)=(2\pi\sigma^2)^{-\frac{1}{2}}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)\]
Log-Density: \[\log f(x | \sigma^2) =-\frac{1}{2} \log(2\pi\sigma^2) - \frac{(x-\mu)^2}{2\sigma^2}\]
Log-likelihood function: \[ \begin{split} l_n(\sigma | D) & = l_n(\mu, \sigma^2 | D) = \sum_{i=1}^n \log f(x_i| \sigma^2)\\ &= -\frac{n}{2}\log(\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2 \underbrace{-\frac{n}{2} \log(2 \pi) }_{\text{constant not depending on } \sigma^2}\\ &= -\frac{n}{2}\log(\sigma^2)-\frac{n}{2\sigma^2} \overline{(x-\mu)^2} + C\\ \end{split} \] Note how the log-likelihood function depends on the data only through \(\overline{(x-\mu)^2}\)!
-
Score function: \[ S_n(\sigma^2) = -\frac{n}{2\sigma^2}+\frac{n}{2\sigma^4} \overline{(x-\mu)^2} \]
Note that to obtain the score function the derivative needs to be taken with regard to the variance parameter \(\sigma^2\) — not with regard to \(\sigma\)! As a trick, relabel \(\sigma^2 = v\) in the log-likelihood function, then take the derivative with regard to \(v\), then backsubstitute \(v=\sigma^2\) in the final result.
Maximum likelihood estimate: \[ S_n(\widehat{\sigma^2}_{ML})=0 \Rightarrow \] \[ \widehat{\sigma^2}_{ML} =\overline{(x-\mu)^2} = \frac{1}{n}\sum_{i=1}^n (x_i-\mu)^2 \]
To confirm that we actually have maximum we need to verify that the second derivative of log-likelihood at the optimum is negative. With \(\frac{dS_n(\sigma^2)}{d\sigma^2} = -\frac{n}{2\sigma^4} \left(\frac{2}{\sigma^2} \overline{(x-\mu)^2} -1\right)\) and hence \(\frac{dS_n( \widehat{\sigma^2}_{ML} )}{d\sigma^2} = -\frac{n}{2} \left(\widehat{\sigma^2}_{ML} \right)^{-2}<0\) the optimum is indeed the maximum.
3.2.2 Likelihood estimation for multiple parameters
If there are several parameters likelihood estimation is conceptually no different from the case of a single parameter. However, the score function is now vector-valued and the second derivative of the log-likelihood is a matrix-valued function.
Example 3.4 Normal distribution with mean and variance both unknown:
- \(x \sim N(\mu,\sigma^2)\) with \(\text{E}(x)=\mu\) and \(\text{Var}(x) = \sigma^2\)
- both \(\mu\) and \(\sigma^2\) need to be estimated.
What’s the MLE of the parameter vector \(\boldsymbol \theta= (\mu,\sigma^2)^T\)?
the data \(D= \{x_1, \ldots, x_n\}\) are all real in the range \(x_i \in [-\infty, \infty]\).
the average \(\bar{x} = \frac{1}{n} \sum_{i=1}^n x_i\) is real as well.
the average of the squared data \(\overline{x^2} = \frac{1}{n} \sum_{i=1}^n x_i^2 \geq 0\) is non-negative.
Density: \[ f(x| \mu, \sigma^2)=(2\pi\sigma^2)^{-\frac{1}{2}}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)\]
Log-Density: \[\log f(x | \mu, \sigma^2) =-\frac{1}{2} \log(2\pi\sigma^2) - \frac{(x-\mu)^2}{2\sigma^2}\]
Log-likelihood function: \[ \begin{split} l_n(\boldsymbol \theta| D) & = l_n(\mu, \sigma^2 | D) = \sum_{i=1}^n \log f(x_i| \mu, \sigma^2)\\ &= -\frac{n}{2}\log(\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2 \underbrace{-\frac{n}{2} \log(2 \pi) }_{\text{constant not depending on }\mu \text{ or } \sigma^2}\\ &= -\frac{n}{2}\log(\sigma^2)-\frac{n}{2\sigma^2} ( \overline{x^2} -2 \bar{x} \mu + \mu^2) + C\\ \end{split} \] Note how the log-likelihood function depends on the data only through \(\bar{x}\) and \(\overline{x^2}\)!
Score function \(\boldsymbol S_n\), gradient of \(l_n(\boldsymbol \theta| D)\): \[ \begin{split} \boldsymbol S_n(\boldsymbol \theta) &= \nabla l_n(\boldsymbol \theta| D) \\ &= \begin{pmatrix} \frac{n}{\sigma^2} (\bar{x}-\mu) \\ -\frac{n}{2\sigma^2}+\frac{n}{2\sigma^4} \left( \overline{x^2} - 2\bar{x} \mu +\mu^2 \right) \\ \end{pmatrix}\\ \end{split} \]
Maximum likelihood estimate: \[ \boldsymbol S_n(\hat{\boldsymbol \theta}_{ML})=0 \Rightarrow \] \[ \hat{\boldsymbol \theta}_{ML}= \begin{pmatrix} \hat{\mu}_{ML} \\ \widehat{\sigma^2}_{ML} \\ \end{pmatrix} = \begin{pmatrix} \bar{x} \\ \overline{x^2} -\bar{x}^2\\ \end{pmatrix} \] The ML estimate of the variance can also be written \(\widehat{\sigma^2}_{ML} = \overline{x^2} -\bar{x}^2 =\overline{(x-\bar{x})^2} = \frac{1}{n}\sum_{i=1}^n (x_i-\bar{x})^2\).
To confirm that we actually have maximum we need to verify that the eigenvalues of the Hessian matrix at the optimum are all negative. This is indeed the case, for details see Example 3.7.
3.2.3 Relationship of maximum likelihood with least squares estimation
In Example 3.2 the form of the log-likelihood function is a function of the sum of squared differences. Maximising \(l_n(\mu| D) =-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2\) is equivalent to minimising \(\sum_{i=1}^n(x_i-\mu)^2\). Hence, finding the mean by maximum likelihood assuming a normal model is equivalent to least-squares estimation!
Note that least-squares estimation has been in use at least since the early 1800s 4 and thus predates maximum likelihood (1922). Due to its simplicity it is still very popular in particular in regression and the link with maximum likelihood and normality allows to understand why it usually works well!
3.2.4 Bias and maximum likelihood estimates
Example 3.4 is interesting because it shows that maximum likelihood can result in both biased and as well as unbiased estimators.
Recall that \(x \sim N(\mu, \sigma^2)\). As a result \[\hat{\mu}_{ML}=\bar{x} \sim N\left(\mu, \frac{\sigma^2}{n}\right)\] with \(\text{E}( \hat{\mu}_{ML} ) = \mu\) and \[ \widehat{\sigma^2}_{\text{ML}} \sim W_1\left(s^2 = \frac{\sigma^2}{n}, k=n-1\right) \] (see Appendix) with mean \(\text{E}(\widehat{\sigma^2}_{ML}) = \frac{n-1}{n} \, \sigma^2\).
Therefore, the MLE of \(\mu\) is unbiased as
\[
\text{Bias}(\hat{\mu}_{ML}) = \text{E}( \hat{\mu}_{ML} ) - \mu = 0
\]
In contrast, however, the MLE of \(\sigma^2\) is negatively biased because
\[
\text{Bias}(\widehat{\sigma^2}_{ML}) = \text{E}( \widehat{\sigma^2}_{ML} ) - \sigma^2 = -\frac{1}{n} \, \sigma^2
\]
Thus, in the case of the variance parameter of the normal distribution the MLE is not recovering the well-known unbiased estimator of the variance
\[
\widehat{\sigma^2}_{UB} = \frac{1}{n-1}\sum_{i=1}^n(x_i-\bar{x})^2 = \frac{n}{n-1} \widehat{\sigma^2}_{ML}
\]
In other words, the unbiased variance estimate is not a maximum likelihood estimate!
Therefore it is worth keeping in mind that maximum likelihood can result in biased estimates for finite \(n\). For large \(n\), however, the bias disappears as MLEs are consistent.
3.3 Observed Fisher information
3.3.1 Motivation and definition
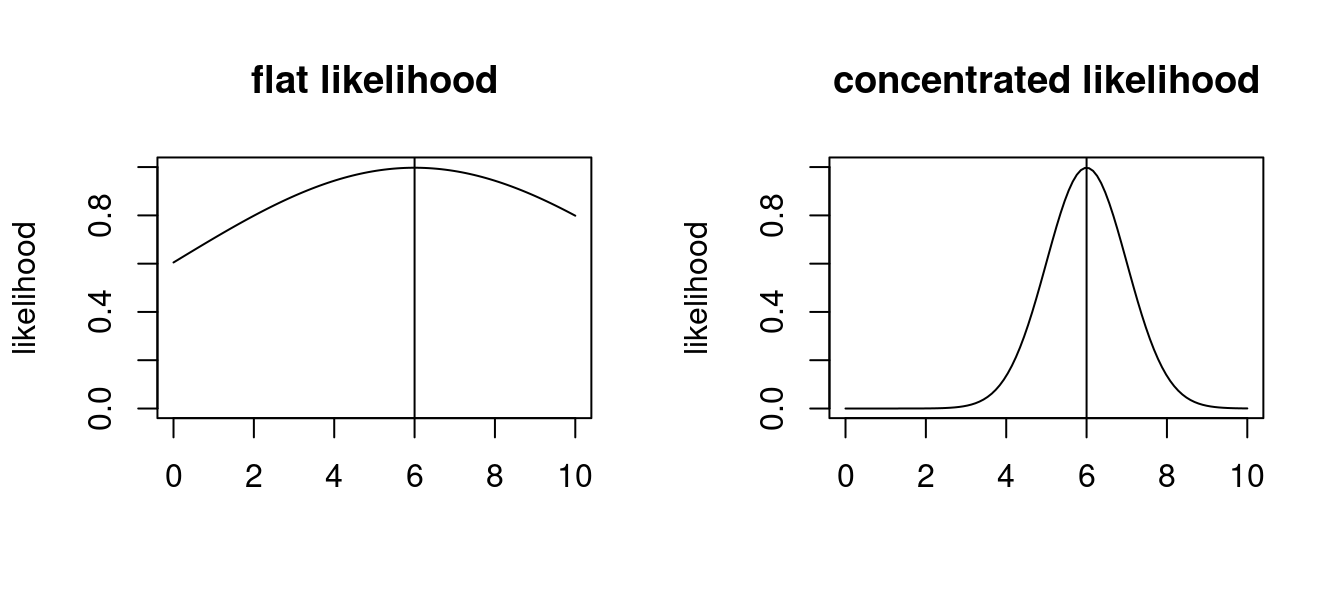
By inspection of some log-likelihood curves it is apparent that the log-likelihood function contains more information about the parameter \(\boldsymbol \theta\) than just the maximum point \(\hat{\boldsymbol \theta}_{ML}\).
In particular the curvature of the log-likelihood function at the MLE must be somehow related the accuracy of \(\hat{\boldsymbol \theta}_{ML}\): if the likelihood surface is flat near the maximum (low curvature) then if is more difficult to find the optimal parameter (also numerically!). Conversely, if the likelihood surface is peaked (strong curvature) then the maximum point is clearly defined.
The curvature is described by the second-order derivatives (Hessian matrix) of the log-likelihood function.
For univariate \(\theta\) the Hessian is a scalar: \[\frac{d^2 l_n(\theta|D)}{d\theta^2}\]
For multivariate parameter vector \(\boldsymbol \theta\) of dimension \(d\) the Hessian is a matrix of size \(d \times d\): \[\nabla \nabla^T l_n(\boldsymbol \theta| D)\]
By construction the Hessian is negative definite at the MLE (i.e. its eigenvalues are all negative) to ensure the the function is concave at the MLE (i.e. peak shaped).
The observed Fisher information (matrix) is defined as the negative curvature at the MLE \(\hat{\boldsymbol \theta}_{ML}\): \[ {\boldsymbol J_n}(\hat{\boldsymbol \theta}_{ML}) = -\nabla \nabla^T l_n(\hat{\boldsymbol \theta}_{ML}| D) \]
Sometimes this is simply called the “observed information”.
To avoid confusion with the expected Fisher information introduced earlier
\[
\boldsymbol I^{\text{Fisher}}(\boldsymbol \theta) = -\text{E}_{F_{\boldsymbol \theta}} \left( \nabla \nabla^T \log f(x|\boldsymbol \theta)\right)
\]
it is necessary to always use the qualifier “observed” when referring to \({\boldsymbol J_n}(\hat{\boldsymbol \theta}_{ML})\).
3.3.2 Examples of observed Fisher information
Example 3.5 Bernoulli model \(\text{Ber}(\theta)\):
We continue Example 3.1. Recall that \(\hat{\theta}_{ML} = \bar{x}=\frac{n_1}{n}\) and the score function \(S_n(\theta)=n \left( \frac{\bar{x} }{\theta} - \frac{1-\bar{x}}{1-\theta} \right)\). The negative second derivative of the log-likelihood function is \[ -\frac{d S_n(\theta)}{d\theta}=n \left( \frac{ \bar{x} }{\theta^2} + \frac{1 - \bar{x} }{(1-\theta)^2} \right) \] The observed Fisher information is therefore \[ \begin{split} J_n(\hat{\theta}_{ML}) & = n \left(\frac{ \bar{x} }{\hat{\theta}_{ML}^2} + \frac{ 1 - \bar{x} }{ (1-\hat{\theta}_{ML})^2 } \right) \\ & = n \left(\frac{1}{\hat{\theta}_{ML}} + \frac{1}{1-\hat{\theta}_{ML}} \right) \\ &= \frac{n}{\hat{\theta}_{ML} (1-\hat{\theta}_{ML})} \\ \end{split} \]
The inverse of the observed Fisher information is: \[J_n(\hat{\theta}_{ML})^{-1}=\frac{\hat{\theta}_{ML}(1-\hat{\theta}_{ML})}{n}\]
Compare this with \(\text{Var}\left(\frac{x}{n}\right) = \frac{\theta(1-\theta)}{n}\) for \(x \sim \text{Bin}(n, \theta)\).
Example 3.6 Normal distribution with unknown mean and known variance:
This is the continuation of Example 3.2. Recall the MLE for the mean \(\hat{\mu}_{ML}=\frac{1}{n}\sum_{i=1}^n x_i=\bar{x}\) and the score function \(\boldsymbol S_n(\mu) = \frac{n}{\sigma^2} (\bar{x} -\mu)\). The negative second derivative of the score function is \[ -\frac{d S_n(\mu)}{d\mu}= \frac{n}{\sigma^2} \] The observed Fisher information at the MLE is therefore \[ J_n(\hat{\mu}_{ML}) = \frac{n}{\sigma^2} \] and the inverse of the observed Fisher information is \[ J_n(\hat{\mu}_{ML})^{-1} = \frac{\sigma^2}{n} \]
For \(x_i \sim N(\mu, \sigma^2)\) we have \(\text{Var}(x_i) = \sigma^2\) and hence \(\text{Var}(\bar{x}) = \frac{\sigma^2}{n}\), which is equal to the inverse observed Fisher information.
Example 3.7 Normal distribution with mean and variance parameter:
This is the continuation of Example 3.4. Recall the MLE for the mean and variance: \[\hat{\mu}_{ML}=\frac{1}{n}\sum_{i=1}^n x_i=\bar{x}\] \[\widehat{\sigma^2}_{ML} = \frac{1}{n}\sum_{i=1}^n(x_i-\bar{x})^2 = \overline{x^2} - \bar{x}^2\] with score function \[\boldsymbol S_n(\mu,\sigma^2)=\nabla l_n(\mu, \sigma^2| D) = \begin{pmatrix} \frac{n}{\sigma^2} (\bar{x}-\mu) \\ -\frac{n}{2\sigma^2}+\frac{n}{2\sigma^4} \left(\overline{x^2} - 2 \mu \bar{x} + \mu^2\right) \\ \end{pmatrix} \] The Hessian matrix of the log-likelihood function is \[\nabla \nabla^T l_n(\mu,\sigma^2| D) = \begin{pmatrix} - \frac{n}{\sigma^2}& -\frac{n}{\sigma^4} (\bar{x} -\mu)\\ - \frac{n}{\sigma^4} (\bar{x} -\mu) & \frac{n}{2\sigma^4}-\frac{n}{\sigma^6} \left(\overline{x^2} - 2 \mu \bar{x} + \mu^2\right) \\ \end{pmatrix} \] The negative Hessian at the MLE, i.e. at \(\hat{\mu}_{ML} = \bar{x}\) and \(\widehat{\sigma^2}_{ML} = \overline{x^2} -\bar{x}^2\) yields the observed Fisher information matrix: \[ \boldsymbol J_n(\hat{\mu}_{ML},\widehat{\sigma^2}_{ML}) = \begin{pmatrix} \frac{n}{\widehat{\sigma^2}_{ML}}&0 \\ 0 & \frac{n}{2(\widehat{\sigma^2}_{ML})^2} \end{pmatrix} \] Note that the observed Fisher information matrix is diagonal with positive entries. Therefore its eigenvalues are all positive as required for a maximum, because for a diagonal matrix the eigenvalues are simply the the entries on the diagonal.
The inverse of the observed Fisher information matrix is \[ \boldsymbol J_n(\hat{\mu}_{ML},\widehat{\sigma^2}_{ML})^{-1} = \begin{pmatrix} \frac{\widehat{\sigma^2}_{ML}}{n}& 0\\ 0 & \frac{2(\widehat{\sigma^2}_{ML})^2}{n} \end{pmatrix} \]
Recall that \(x \sim N(\mu, \sigma^2)\) and therefore \[\hat{\mu}_{ML}=\bar{x} \sim N\left(\mu, \frac{\sigma^2}{n}\right)\] Hence \(\text{Var}(\hat{\mu}_{ML}) = \frac{\sigma^2}{n}\). If you compare this with the first diagonal entry of the inverse observed Fisher information matrix you see that this is essentially the same expression (apart from the “hat”).
The empirical variance \(\widehat{\sigma^2}_{ML}\) follows a one-dimensional Wishart distribution \[ \widehat{\sigma^2}_{\text{ML}} \sim W_1\left(s^2 = \frac{\sigma^2}{n}, k=n-1\right) \] (see Appendix) with variance \(\text{Var}(\widehat{\sigma^2}_{ML}) = \frac{n-1}{n} \, \frac{2 \sigma ^4}{n}\). For large \(n\) this becomes \(\text{Var}(\widehat{\sigma^2}_{ML})\overset{a}{=} \frac{2 \sigma ^4}{n}\) which is essentially (apart from the “hat”) the second diagonal entry of the inverse observed Fisher information matrix.
3.3.3 Relationship between observed and expected Fisher information
The observed Fisher information \(\boldsymbol J_n(\hat{\boldsymbol \theta}_{ML})\) and the expected Fisher information \(\boldsymbol I^{\text{Fisher}}(\boldsymbol \theta)\) are related but also two clearly different entities:
Both types of Fisher information are based on computing second order derivatives (Hessian matrix), thus both are based on the curvature of a function.
The observed Fisher information is computed from the log-likelihood function. Therefore it takes the observed data \(D\) into account and explicitly depends on the sample size \(n\). It contains estimates of the parameters but not the parameters themselves. While the curvature of the log-likelihood function may be computed for any point of the log-likelihood function the observed Fisher information specifically refers to curvature at the MLE \(\hat{\boldsymbol \theta}_{ML}\). It is linked to the (asymptotic) variance of the MLE as we have seen in the examples and will discuss in more detail later.
In contrast, the expected Fisher information is derived directly from the log-density. It does not depend on the observed data, and thus does not depend on sample size. It can be computed for any value of the parameters. It describes the geometry of the space of the models, and is the local approximation of relative entropy.
Assume that for large sample size \(n\) the MLE converges to \(\hat{\boldsymbol \theta}_{ML} \rightarrow \boldsymbol \theta_0\). It follows from the construction of the observed Fisher information and the law of large numbers that asymptotically for large sample size \(\boldsymbol J_n(\hat{\boldsymbol \theta}_{ML}) \rightarrow n \boldsymbol I^{\text{Fisher}}( \boldsymbol \theta_0 )\) (i.e. the expected Fisher information for a set of iid random variables, see Example 2.14).
In a very important class of models, namely in an exponential family model, we find that \(\boldsymbol J_n(\hat{\boldsymbol \theta}_{ML}) = n \boldsymbol I^{\text{Fisher}}( \hat{\boldsymbol \theta}_{ML} )\) is valid also for finite sample size \(n\). This is in fact the case for all the examples discussed above (e.g. see Examples 3.5 and 2.11 for the Bernoulli distribution and Examples 3.7 and 2.13 for the normal distribution).
However, this is an exception. In a general model \(\boldsymbol J_n(\hat{\boldsymbol \theta}_{ML}) \neq n \boldsymbol I^{\text{Fisher}}( \hat{\boldsymbol \theta}_{ML} )\) for finite sample size \(n\). An example is provided by the Cauchy distribution with median parameter \(\theta\). It is not an exponential family model and has expected Fisher information \(I^{\text{Fisher}}(\theta )=\frac{1}{2}\) regardless of the choice the median parameter whereas the observed Fisher information \(J_n(\hat{\theta}_{ML})\) depends on the MLE \(\hat{\theta}_{ML}\) of the median parameter and is not simply \(\frac{n}{2}\).