
4 Quadratic approximation and normal asymptotics
4.1 Approximate distribution of maximum likelihood estimates
Quadratic log-likelihood of the multivariate normal model
Assume we observe a single sample \(\symbfit x\sim N(\symbfit \mu, \symbfit \Sigma)\) with known covariance. Noting that the multivariate normal density is \[ f(\symbfit x| \symbfit \mu, \symbfit \Sigma) = (2\pi)^{-\frac{d}{2}} \det(\symbfit \Sigma)^{-\frac{1}{2}} \exp\left(-\frac{1}{2} (\symbfit x-\symbfit \mu)^T \symbfit \Sigma^{-1} (\symbfit x-\symbfit \mu) \right) \] the corresponding log-likelihood for \(\symbfit \mu\) is \[ l_1(\symbfit \mu| \symbfit x) = C - \frac{1}{2}(\symbfit x-\symbfit \mu)^T \symbfit \Sigma^{-1} (\symbfit x-\symbfit \mu) \] where \(C\) is a constant that does not depend on \(\symbfit \mu\). Note that the log-likelihood is a quadratic function (both for \(\symbfit x\) and \(\symbfit \mu\)) and the maximum of the function lies at \(\symbfit \mu= \symbfit x\) with value \(C\).
Quadratic approximation of a log-likelihood function
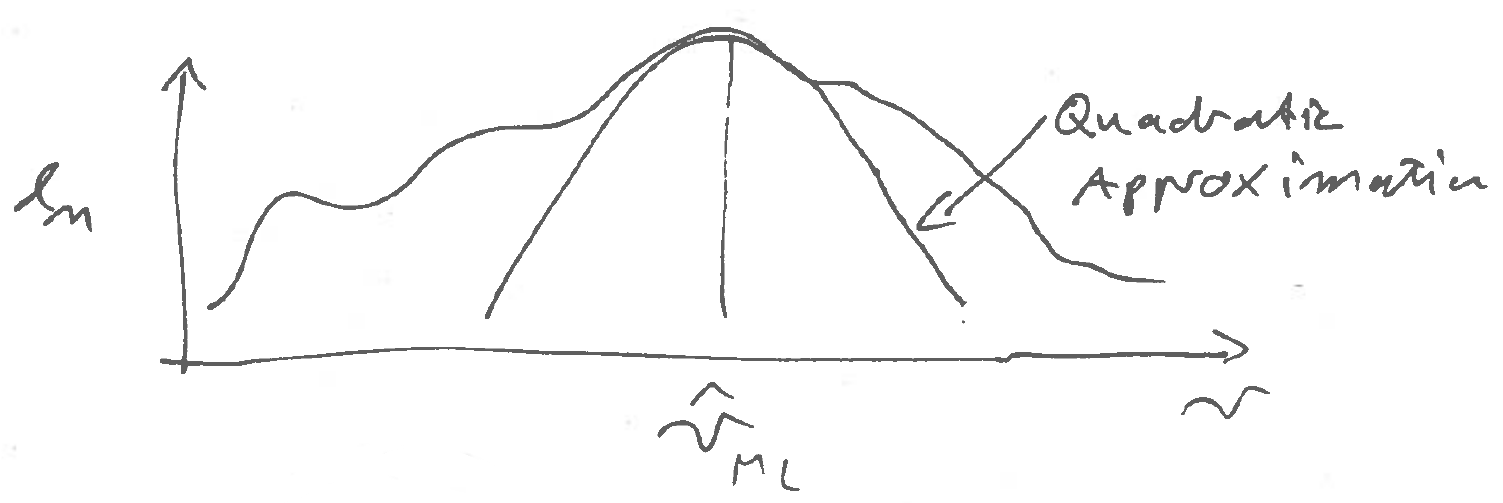
Now consider the quadratic approximation of a general log-likelihood function \(l_n(\symbfit \theta| D)\) for \(\symbfit \theta\) around the MLE \(\hat{\symbfit \theta}_{ML}\) (Figure 4.1).
We assume the underlying model is regular and that \(\nabla l_n(\hat{\symbfit \theta}_{ML} | D) = 0\), i.e. the gradient at the maximum vanishes. The Taylor series approximation of scalar-valued function \(f(\symbfit x)\) around \(\symbfit x_0\) is \[ f(\symbfit x) = f(\symbfit x_0) + \nabla^T f(\symbfit x_0)\, (\symbfit x-\symbfit x_0) + \frac{1}{2} (\symbfit x-\symbfit x_0)^T \nabla \nabla^T f(\symbfit x_0) (\symbfit x-\symbfit x_0) + \ldots \] Applied to the log-likelihood function this yields
\[l_n(\symbfit \theta| D) \approx l_n(\hat{\symbfit \theta}_{ML} | D)- \frac{1}{2}(\hat{\symbfit \theta}_{ML}- \symbfit \theta)^T J_n(\hat{\symbfit \theta}_{ML})(\hat{\symbfit \theta}_{ML}-\symbfit \theta)\]
This is a quadratic function with maximum at \(( \hat{\symbfit \theta}_{ML}, l_n(\hat{\symbfit \theta}_{ML} | D) )\). Note the appearance of the observed Fisher information \(J_n(\hat{\symbfit \theta}_{ML})\) in the quadratic term. There is no linear term because of the vanishing gradient at the MLE.
Crucially, this approximated log-likelihood takes the same form as if \(\hat{\symbfit \theta}_{ML}\) was sampled from a multivariate normal distribution with mean \(\symbfit \theta\) and with covariance given by the inverse observed Fisher information.
Note that this requires a positive definite observed Fisher information matrix so that \(J_n(\hat{\symbfit \theta}_{ML})\) is actually invertible!
Example 4.1 Quadratic approximation of the log-likelihood for a proportion:
From Example 3.1 we have the log-likelihood \[ l_n(p | D) = n \left( \bar{x} \log p + (1-\bar{x}) \log(1-p) \right) \] and the MLE \[ \hat{p}_{ML} = \bar{x} \] and from Example 3.7 the observed Fisher information \[ \begin{split} J_n(\hat{p}_{ML}) = \frac{n}{\bar{x} (1-\bar{x})} \end{split} \] The log-likelihood at the MLE is \[ l_n(\hat{p}_{ML} | D) = n \left( \bar{x} \log \bar{x} + (1-\bar{x}) \log(1-\bar{x}) \right) \] This allows us to construct the quadratic approximation of the log-likelihood around the MLE as \[ \begin{split} l_n(p| D) & \approx l_n(\hat{p}_{ML} | D) - \frac{1}{2} J_n(\hat{p}_{ML}) (p-\hat{p}_{ML})^2 \\ &= n \left( \bar{x} \log \bar{x} + (1-\bar{x}) \log(1-\bar{x}) - \frac{(p-\bar{x})^2}{2 \bar{x} (1-\bar{x})} \right) \\ &= C + \frac{ \bar{x} p -\frac{1}{2} p^2}{ \bar{x} (1-\bar{x})/n} \\ \end{split} \] The constant \(C\) does not depend on \(p\), its function is to match the approximate log-likelihood at the MLE with that of the corresponding original log-likelihood. The approximate log-likelihood takes on the form of a normal log-likelihood (Example 3.2) for one observation of \(\hat{p}_{ML}=\bar{x}\) from \(N\left(p, \frac{\bar{x} (1-\bar{x})}{n} \right)\).
Figure 4.2 shows the Bernoulli log-likelihood function and its quadratic approximation illustrated for data with \(n = 30\) and \(\bar{x} = 0.7\):
Asymptotic normality of maximum likelihood estimates
Intuitively, it makes sense to associate large amount of curvature of the log-likelihood at the MLE with low variance of the MLE (and conversely, low amount of curvature with high variance).
From the above we see that
- normality implies a quadratic log-likelihood,
- conversely, taking an quadratic approximation of the log-likelihood implies approximate normality, and
- in the quadratic approximation the inverse observed Fisher information plays the role of the covariance of the MLE.
This suggests the following theorem: Asymptotically, the MLE is normally distributed around the true parameter and with covariance equal to the inverse of the observed Fisher information:
\[\hat{\symbfit \theta}_{ML} \overset{a}{\sim}\underbrace{N_d}_{\text{multivariate normal}}\left(\underbrace{\symbfit \theta}_{\text{mean vector}},\underbrace{\symbfit J_n(\hat{\symbfit \theta}_{ML})^{-1}}_{\text{ covariance matrix}}\right)\]
This theorem about the distributional properties of MLEs greatly enhances the usefulness of the method of maximum likelihood. It implies that in regular settings maximum likelihood is not just a method for obtaining point estimates but also also provides estimates of their uncertainty.
However, we need to clarify what “asymptotic” actually means in the context of the above theorem:
Primarily, it means to have sufficient sample size so that the log-likelihood \(l_n(\symbfit \theta)\) is sufficiently well approximated by a quadratic function around \(\hat{\symbfit \theta}_{ML}\). The better the local quadratic approximation the better the normal approximation!
In a regular model with positive definite observed Fisher information matrix this is guaranteed for large sample size \(n \rightarrow \infty\) thanks to the central limit theorem).
However, \(n\) going to infinity is in fact not always required for the normal approximation to hold! Depending on the particular model a good local fit to a quadratic log-likelihood may be available also for finite \(n\). As a trivial example, for the normal log-likelihood it is valid for any \(n\).
In the other hand, in non-regular models (with nondifferentiable log-likelihood at the MLE and/or a singular Fisher information matrix) no amount of data, not even \(n\rightarrow \infty\), will make the quadratic approximation work.
Remarks:
- The asymptotic normality of MLEs was first discussed in Fisher (1925) 1
The technical details of the above considerations are worked out in the theory of locally asymptotically normal (LAN) models pioneered in 1960 by Lucien LeCam (1924–2000).
There are also methods to obtain higher-order (higher than quadratic and thus non-normal) asymptotic approximations. These relate to so-called saddle point approximations.
Asymptotic optimal efficiency
Assume now that \(\hat{\symbfit \theta}\) is an arbitrary and unbiased estimator for \(\symbfit \theta\) and the underlying data generating model is regular with density \(f(\symbfit x| \symbfit \theta)\).
H. Cramér (1893–1985), C. R. Rao (1920–) and others demonstrated in 1945 the so-called information inequality, \[ \text{Var}(\hat{\symbfit \theta}) \geq \frac{1}{n} \symbfit I^{\text{Fisher}}(\symbfit \theta)^{-1} \] which puts a lower bound on the variance of an estimator for \(\symbfit \theta\). (Note for \(d>1\) this is a matrix inequality, meaning that the difference matrix is positive semidefinite).
For large sample size with \(n \rightarrow \infty\) and \(\hat{\symbfit \theta}_{ML} \rightarrow \symbfit \theta\) the observed Fisher information becomes \(J_n(\hat{\symbfit \theta}) \rightarrow n \symbfit I^{\text{Fisher}}(\symbfit \theta)\) and therefore we can write the asymptotic distribution of \(\hat{\symbfit \theta}_{ML}\) as \[ \hat{\symbfit \theta}_{ML} \overset{a}{\sim} N_d\left( \symbfit \theta, \frac{1}{n} \symbfit I^{\text{Fisher}}(\symbfit \theta)^{-1} \right) \] This means that for large \(n\) in regular models \(\hat{\symbfit \theta}_{ML}\) achieves the lowest variance possible according to the Cramér-Rao information inequality. In other words, for large sample size maximum likelihood is optimally efficient and thus the best available estimator will in fact be the MLE!
However, as we will see later this does not hold for small sample size where it is indeed possible (and necessary) to improve over the MLE (e.g. via Bayesian estimation or regularisation).
4.2 Quantifying the uncertainty of maximum likelihood estimates
Estimating the variance of MLEs
In the previous section we saw that MLEs are asymptotically normally distributed, with the inverse Fisher information (both expected and observed) linked to the asymptotic variance.
This leads to the question whether to use the observed Fisher information \(J_n(\hat{\symbfit \theta}_{ML})\) or the expected Fisher information at the MLE \(n \symbfit I^{\text{Fisher}}( \hat{\symbfit \theta}_{ML} )\) to estimate the variance of the MLE?
- Clearly, for \(n\rightarrow \infty\) both can be used interchangeably.
- However, they can be very different for finite \(n\) in particular for models that are not exponential families.
- Also normality may occur well before \(n\) goes to \(\infty\).
Therefore one needs to choose between the two, considering also that
- the expected Fisher information at the MLE is the average curvature at the MLE, whereas the observed Fisher information is the actual observed curvature, and
- the observed Fisher information naturally occurs in the quadratic approximation of the log-likelihood.
All in all, the observed Fisher information as estimator of the variance is more appropriate as it is based on the actual observed data and also works for large \(n\) (in which case it yields the same result as using expected Fisher information): \[ \widehat{\text{Var}}(\hat{\symbfit \theta}_{ML}) = \symbfit J_n(\hat{\symbfit \theta}_{ML})^{-1} \] and its square-root as the estimate of the standard deviation \[ \widehat{\text{SD}}(\hat{\symbfit \theta}_{ML}) = \symbfit J_n(\hat{\symbfit \theta}_{ML})^{-1/2} \] Note that in the above we use matrix inversion and the (inverse) matrix square root.
The reasons for preferring observed Fisher information are made mathematically precise in a classic paper by Efron and Hinkley (1978) 2 .
Examples for the estimated variance and asymptotic normal distribution
Example 4.2 Estimated variance and distribution of the MLE of a proportion:
From Example 3.1 and Example 3.7 we know the MLE \[ \hat{p}_{ML} = \bar{x} = \frac{k}{n} \] and the corresponding observed Fisher information \[ J_n(\hat{p}_{ML})=\frac{n}{\hat{p}_{ML}(1-\hat{p}_{ML})} \] The estimated variance of the MLE is therefore \[ \widehat{\text{Var}}( \hat{p}_{ML} ) = \frac{\hat{p}_{ML}(1-\hat{p}_{ML})}{n} \] and the corresponding asymptotic normal distribution is \[ \hat{p}_{ML} \overset{a}{\sim} N\left(p, \frac{\hat{p}_{ML}(1-\hat{p}_{ML})}{n} \right) \]
Example 4.3 Estimated variance and distribution of the MLE of the mean parameter for the normal distribution with known variance:
From Example 3.2 and Example 3.8 we know that \[\hat{\mu}_{ML} =\bar{x}\] and that the corresponding observed Fisher information at \(\hat{\mu}_{ML}\) is \[J_n(\hat{\mu}_{ML})=\frac{n}{\sigma^2}\]
The estimated variance of the MLE is therefore \[ \widehat{\text{Var}}(\hat{\mu}_{ML}) = \frac{\sigma^2}{n} \] and the corresponding asymptotic normal distribution is \[ \hat{\mu}_{ML} \sim N\left(\mu,\frac{\sigma^2}{n}\right) \]
Note that in this case the distribution is not asymptotic but is exact, i.e. valid also for small \(n\) (as long as the data \(x_i\) are actually from \(N(\mu, \sigma^2)\)!).
Wald statistic
Centering the MLE \(\hat{\symbfit \theta}_{ML}\) with \(\symbfit \theta_0\) followed by standardising with \(\widehat{\text{SD}}(\hat{\symbfit \theta}_{ML})\) yields the Wald statistic (named after Abraham Wald, 1902–1950): \[ \begin{split} \symbfit t(\symbfit \theta_0) & = \widehat{\text{SD}}(\hat{\symbfit \theta}_{ML})^{-1}(\hat{\symbfit \theta}_{ML}-\symbfit \theta_0)\\ & = \symbfit J_n(\hat{\symbfit \theta}_{ML})^{1/2}(\hat{\symbfit \theta}_{ML}-\symbfit \theta_0)\\ \end{split} \] The squared Wald statistic is a scalar defined as \[ \begin{split} t(\symbfit \theta_0)^2 &= \symbfit t(\symbfit \theta_0)^T \symbfit t(\symbfit \theta_0) \\ &= (\hat{\symbfit \theta}_{ML}-\symbfit \theta_0)^T \symbfit J_n(\hat{\symbfit \theta}_{ML}) (\hat{\symbfit \theta}_{ML}-\symbfit \theta_0)\\ \end{split} \] Note that in the literature both \(\symbfit t(\symbfit \theta_0)\) and \(t(\symbfit \theta_0)^2\) are commonly referred to as Wald statistics. In this text we use the qualifier “squared” if we refer to the latter.
We now assume that the true underlying parameter is \(\symbfit \theta_0\). Since the MLE is asymptotically normal the Wald statistic is asymptotically standard normal distributed: \[\begin{align*} \begin{array}{cc} \symbfit t(\symbfit \theta_0) \overset{a}{\sim}\\ t(\theta_0) \overset{a}{\sim}\\ \end{array} \begin{array}{ll} N_d(\symbfup 0_d,\symbfit I_d)\\ N(0,1)\\ \end{array} \begin{array}{ll} \text{for vector } \symbfit \theta\\ \text{for scalar } \theta\\ \end{array} \end{align*}\] Correspondingly, the squared Wald statistic is chi-squared distributed: \[\begin{align*} \begin{array}{cc} t(\symbfit \theta_0)^2 \\ t(\theta_0)^2\\ \end{array} \begin{array}{ll} \overset{a}{\sim}\chi^2_d\\ \overset{a}{\sim}\chi^2_1\\ \end{array} \begin{array}{ll} \text{for vector } \symbfit \theta\\ \text{for scalar } \theta\\ \end{array} \end{align*}\] The degree of freedom of the chi-squared distribution is the dimension \(d\) of the parameter vector \(\symbfit \theta\).
Examples of the (squared) Wald statistic
Example 4.4 Wald statistic for a proportion:
We continue from Example 4.2. With \(\hat{p}_{ML} = \bar{x}\) and \(\widehat{\text{Var}}( \hat{p}_{ML} ) = \frac{\hat{p}_{ML}(1-\hat{p}_{ML})}{n}\) and thus \(\widehat{\text{SD}}( \hat{p}_{ML} ) =\sqrt{ \frac{\hat{p}_{ML}(1-\hat{p}_{ML})}{n} }\) we get as Wald statistic:
\[ t(p_0) = \frac{\bar{x}-p_0}{ \sqrt{\bar{x}(1-\bar{x}) / n } }\overset{a}{\sim} N(0,1) \]
The squared Wald statistic is: \[t(p_0)^2 = n \frac{(\bar{x}-p_0)^2}{ \bar{x}(1-\bar{x}) }\overset{a}{\sim} \chi^2_1 \]
Example 4.5 Wald statistic for the mean parameter of a normal distribution with known variance:
We continue from Example 4.3. With \(\hat{\mu}_{ML} =\bar{x}\) and \(\widehat{\text{Var}}(\hat{\mu}_{ML}) = \frac{\sigma^2}{n}\) and thus \(\widehat{\text{SD}}(\hat{\mu}_{ML}) = \frac{\sigma}{\sqrt{n}}\) we get as Wald statistic:
\[t(\mu_0) = \frac{\bar{x}-\mu_0}{\sigma / \sqrt{n}}\sim N(0,1)\] Note this is the one sample \(t\)-statistic with given \(\sigma\). The squared Wald statistic is: \[t(\mu_0)^2 = \frac{(\bar{x}-\mu_0)^2}{\sigma^2 / n}\sim \chi^2_1 \]
Again, in this instance this is the exact distribution, not just the asymptotic one.
Using the Wald statistic or the squared Wald statistic we can test whether a particular \(\mu_0\) can be rejected as underlying true parameter, and we can also construct corresponding confidence intervals.
Example 4.6 Wald statistic for the categorical distribution:
The squared Wald statistic is \[ \begin{split} t(\symbfit p_0)^2 &= (\hat{\pi}_{1}^{ML}-p_1^0, \ldots, \hat{\pi}_{K-1}^{ML}-p_{K-1}^0) \symbfit J_n(\hat{\pi}_{1}^{ML}, \ldots, \hat{\pi}_{K-1}^{ML} ) \begin{pmatrix} \hat{\pi}_{1}^{ML}-p_1^0 \\ \vdots \\ \hat{\pi}_{K-1}^{ML}-p_{K-1}^0\\ \end{pmatrix}\\ &= n \left( \sum_{k=1}^{K-1} \frac{(\hat{\pi}_{k}^{ML}-p_{k}^0)^2}{\hat{\pi}_{k}^{ML}} + \frac{ \left(\sum_{k=1}^{K-1} (\hat{\pi}_{k}^{ML}-p_{k}^0)\right)^2}{\hat{\pi}_{K}^{ML}} \right) \\ &= n \left( \sum_{k=1}^{K} \frac{(\hat{\pi}_{k}^{ML}-p_{k}^0)^2}{\hat{\pi}_{k}^{ML}} \right) \\ & = n D_{\text{Neyman}}( \text{Cat}(\hat{\symbfit \pi}_{ML}), \text{Cat}(\symbfit p_0 ) ) \end{split} \]
With \(n_1, \ldots, n_K\) the observed counts with \(n = \sum_{k=1}^K n_k\) and \(\hat{\pi}_k^{ML} = \frac{n_k}{n} = \bar{x}_k\), and \(n_1^{\text{expect}}, \ldots, n_K^{\text{expect}}\) the expected counts \(n_k^{\text{expect}} = n p_k^{0}\) under \(\symbfit p_0\) we can write the squared Wald statistic as follows: \[ t(\symbfit p_0)^2 = \sum_{k=1}^K \frac{(n_k-n_k^{\text{expect}} )^2}{n_k} = \chi^2_{\text{Neyman}} \] This is known as the Neyman chi-squared statistic (note the observed counts in its denominator) and it is asymptotically distributed as \(\chi^2_{K-1}\) because there are \(K-1\) free parameters in \(\symbfit p_0\).
Normal confidence intervals using the Wald statistic
See Section A.10 to review relevant background from year 1.

The asymptotic normality of MLEs derived from regular models enables us to construct a corresponding normal confidence interval (Figure 4.3). For example, to construct the asymptotic normal CI for the MLE of a scalar parameter \(\theta\) we use the MLE \(\hat{\theta}_{ML}\) as estimate of the mean and its standard deviation \(\widehat{\text{SD}}(\hat{\theta}_{ML})\) computed from the observed Fisher information: \[ \text{CI}=[\hat{\theta}_{ML} \pm c_{\text{normal}} \widehat{\text{SD}}(\hat{\theta}_{ML})] \] Here \(c_{normal}\) is a critical value for the standard-normal symmetric confidence interval chosen to achieve the desired nominal coverage. The critical values are computed using the inverse standard normal distribution function via \(c_{\text{normal}}=\Phi^{-1}\left(\frac{1+\kappa}{2}\right)\). A list of critical values for the standard normal distribution is found in Table A.1. For example, for a CI with 95% coverage one uses the factor 1.96 so that \[\text{CI}=[\hat{\theta}_{ML} \pm 1.96\, \widehat{\text{SD}}(\hat{\theta}_{ML}) ]\]
The normal CI can be expressed using Wald statistic as follows: \[ \text{CI}=\{\theta_0: | t(\theta_0)| < c_{\text{normal}} \} \]
Similary, it can also be expressed using the squared Wald statistic: \[ \text{CI}=\{\theta_0: t(\symbfit \theta_0)^2 < c_{\text{chisq}} \} \] Note that this form facilitates the construction of normal confidence intervals for a parameter vector \(\symbfit \theta_0\).
A list of critical values for the chi-squared distribution with one degree of freedom is found in Table A.2.
The following lists contains the critical values resulting from the chi-squared distribution with degree of freedom \(m=1\) for the three most common choices of coverage \(\kappa\) for a normal CI for a univariate parameter: For example, for a 95% interval the critical value equals 3.84 (which is the square of the critical value 1.96 for the standard normal).
Normal tests using the Wald statistic
Finally, recall the duality between confidence intervals and statistical tests. Specifically, a confidence interval with coverage \(\kappa\) can be also used for testing as follows:
- for every \(\theta_0\) inside the CI the data do not allow to reject the hypothesis that \(\theta_0\) is the true parameter with significance level \(1-\kappa\).
- Conversely, all values \(\theta_0\) outside the CI can be rejected to be the true parameter with significance level \(1-\kappa\) .
Hence, in order to test whether \(\symbfit \theta_0\) is the true underlying parameter value we can compute the corresponding (squared) Wald statistic, find the desired critical value and then decide on rejection.
Examples for normal confidence intervals and corresponding tests
Example 4.7 Asymptotic normal confidence interval for a proportion:
We continue from Example 4.2 and Example 4.4. Assume we observe \(n=30\) measurements with average \(\bar{x} = 0.7\). Then \(\hat{p}_{ML} = \bar{x} = 0.7\) and \(\widehat{\text{SD}}(\hat{p}_{ML}) = \sqrt{ \frac{ \bar{x}(1-\bar{x})}{n} } \approx 0.084\).
The symmetric asymptotic normal CI for \(p\) with 95% coverage is given by \(\hat{p}_{ML} \pm 1.96 \, \widehat{\text{SD}}(\hat{p}_{ML})\) which for the present data results in the interval \([0.536, 0.864]\).
Example 4.8 Asymptotic normal test for a proportion:
We continue from Example 4.7.
We now consider two possible values (\(p_0=0.5\) and \(p_0=0.8\)) as potentially true underlying proportion.
The value \(p_0=0.8\) lies inside the 95% confidence interval \([0.536, 0.864]\). This implies we cannot reject the hypthesis that this is the true underlying parameter on 5% significance level. In contrast, \(p_0=0.5\) is outside the confidence interval so we can indeed reject this value. In other words, data plus model exclude this value as statistically implausible.
This can be verified more directly by computing the corresponding (squared) Wald statistics (see Example 4.4) and comparing them with the relevant critical value (3.84 from chi-squared distribution for 5% significance level):
- \(t(0.5)^2 = \frac{(0.7-0.5)^2}{0.084^2} = 5.71 > 3.84\) hence \(p_0=0.5\) can be rejected.
- \(t(0.8)^2 = \frac{(0.7-0.8)^2}{0.084^2} = 1.43 < 3.84\) hence \(p_0=0.8\) cannot be rejected.
Note that the squared Wald statistic at the boundaries of the normal confidence interval is equal to the critical value.
Example 4.9 Normal confidence interval for the mean:
We continue from Example 4.3 and Example 4.5. Assume that we observe \(n=25\) measurements with average \(\bar{x} = 10\), from a normal with unknown mean and variance \(\sigma^2=4\).
Then \(\hat{\mu}_{ML} = \bar{x} = 10\) and \(\widehat{\text{SD}}(\hat{\mu}_{ML}) = \sqrt{ \frac{ \sigma^2}{n} } = \frac{2}{5}\).
The symmetric asymptotic normal CI for \(p\) with 95% coverage is given by \(\hat{\mu}_{ML} \pm 1.96 \, \widehat{\text{SD}}(\hat{\mu}_{ML})\) which for the present data results in the interval \([9.216, 10.784]\).
Example 4.10 Normal test for the mean:
We continue from Example 4.9.
We now consider two possible values (\(\mu_0=9.5\) and \(\mu_0=11\)) as potentially true underlying mean parameter.
The value \(\mu_0=9.5\) lies inside the 95% confidence interval \([9.216, 10.784]\). This implies we cannot reject the hypthesis that this is the true underlying parameter on 5% significance level. In contrast, \(\mu_0=11\) is outside the confidence interval so we can indeed reject this value. In other words, data plus model exclude this value as a statistically implausible.
This can be verified more directly by computing the corresponding (squared) Wald statistics (see Example 4.5) and comparing them with the relevant critical values:
- \(t(9.5)^2 = \frac{(10-9.5)^2}{4/25}= 1.56 < 3.84\) hence \(\mu_0=9.5\) cannot be rejected.
- \(t(11)^2 = \frac{(10-11)^2}{4/25} = 6.25 > 3.84\) hence \(\mu_0=11\) can be rejected.
The squared Wald statistic at the boundaries of the confidence interval equals the critical value.
Note that this is the standard one-sample test of the mean, and that it is exact, not an approximation.
4.3 Example of a non-regular model
Not all models allow a quadratic approximation of the log-likelihood function around the MLE. This is the case when the log-likelihood function is not differentiable at the MLE. These models are called non-regular and for those models the normal approximation is not available.
Example 4.11 Uniform distribution with upper bound \(\theta\): \[x_1,\dots,x_n \sim U(0,\theta)\] With \(x_{[i]}\) we denote the ordered observations with \(0 \leq x_{[1]} < x_{[2]} < \ldots < x_{[n]} \leq \theta\) and \(x_{[n]} = \max(x_1,\dots,x_n)\).
We would like to obtain both the maximum likelihood estimator \(\hat{\theta}_{ML}\) and its distribution.
The probability density function of \(U(0,\theta)\) is \[p(x|\theta) =\begin{cases} \frac{1}{\theta} &\text{if } x \in [0,\theta] \\ 0 & \text{otherwise.} \end{cases} \] and corresponding the log-density \[ \log p(x|\theta) =\begin{cases} - \log \theta &\text{if } x \in [0,\theta] \\ - \infty & \text{otherwise.} \end{cases} \]
Since all observed data \(D =\{x_1, \ldots, x_n\}\) lie in the interval \([0,\theta]\) the log-likelihood function is \[ l_n(\theta| D) =\begin{cases} -n\log \theta &\text{for } \theta \geq x_{[n]}\\ - \infty & \text{otherwise} \end{cases} \] Note that the log-likelihood is a function of \(x_{[n]}\) only so this single data point is the sufficient statistic. The log-likelihood function remains at value \(-\infty\) until \(\theta = x_{[n]}\), where it jumps to \(-n\log x_{[n]}\) and then it decreases monotonically with increasing \(\theta > x_{[n]}\). Hence the log-likelihood function has a maximum at \(\hat{\theta}_{ML}=x_{[n]}\).
Due to the discontinuity in \(l_n(\theta| D)\) at \(x_{[n]}\) the log-likelihood \(l_n(\theta| D)\) is not differentiable at \(\hat{\theta}_{ML}\). Thus, there is no quadratic approximation around \(\hat{\theta}_{ML}\) and the observed Fisher information cannot be computed. Hence, the normal approximation for the distribution of \(\hat{\theta}_{ML}\) is not valid regardless of sample size, i.e. not even asymptotically for \(n \rightarrow \infty\).
Nonetheless, one can still obtain the sampling distribution of \(\hat{\theta}_{ML}=x_{[n]}\). However, not via asymptotic arguments but instead by understanding that \(x_{[n]}\) is an order statistic (see https://en.wikipedia.org/wiki/Order_statistic) with the following properties: \[\begin{align*} \begin{array}{cc} x_{[n]}\sim \theta \, \text{Beta}(n,1)\\ \\ \text{E}(x_{[n]})=\frac{n}{n+1} \theta\\ \\ \text{Var}(x_{[n]})=\frac{n}{(n+1)^2(n+2)}\theta^2\\ \end{array} \begin{array}{ll} \text{"n-th order statistic" }\\ \\ \\ \\ \approx \frac{\theta^2}{n^2}\\ \end{array} \end{align*}\]
Note that the variance decreases with \(\frac{1}{n^2}\) which is much faster than the usual \(\frac{1}{n}\) of an “efficient” estimator. Correspondingly, \(\hat{\theta}_{ML}\) is a so-called “super efficient” estimator.
Fisher R. A. 1925. Theory of statistical estimation. Math. Proc. Cambridge Philos. Soc. 22:700–725. https://doi.org/10.1017/S0305004100009580↩︎
Efron, B., and D. V. Hinkley. 1978. Assessing the accuracy of the maximum likelihood estimator: observed versus expected Fisher information. Biometrika 65:457–482. https://doi.org/10.1093/biomet/65.3.457↩︎