Korbinian Strimmer, Uni Leipzig, Wintersemester 2010/11
Beginn: 11. Oktober 2010Zeit: Dienstag 11-12:30
Ort: Seminarraum 109, Härtelstr. 16-18
Synopsis:
Ziel der Vorlesung ist es, die konzeptionellen Grundlagen des maschinellen Lernes zu verstehen. Ein Großteil der Vorlesung beschäftigt sich mit statistischen Lernverfahren und Informationstheorie.
Geplante Inhalte:
- Zufallsvariablen und Wahrscheinlichkeitstheorie
- Stochastische Modellierung
- Entropy und Information
- Maximum likelihood und Bayesianische Inferenz
- Clustering und Klassifikation
- Resampling Verfahren (Bootstrap und MCMC)
- Modellwahl und Hypothesentesten
- Hochdimensionale Statistik und Regularisierung
- Analyse räumlich-zeitlich korrellierter Daten
Empfohlene Literatur:
- D. R. Cox. 2006. Principles of statistical inference. CUP.
- F. M. Dekking et al. 2005. A modern introduction to probability and statistics: understanding why and how. Springer.
- P. J. Diggle. 1990. Time Series: A Biostatistical Introduction. OUP.
- P. J. Diggle und P. J. Ribeiro Jr. 2007. Model-based geostatistics. Springer.
- T. Hastie, R. Tibshirani, and J. Friedman. 2001. The elements of statistical learning. Springer.
- M. L. Lavine. 2005. Introduction to statistical thought.
- D. J. C. MacKay. 2003. Information theory, inference, and learning algorithms. CUP.
- R Project for Statistical Computing: http://www.r-project.org
Parallel zur Vorlesung entsteht ein Skript (in Englisch) mit dem Titel "Statistical Thinking", in dem Sie alle wichtigen Formel und Konzepte nachlesen können. Das für jede Vorlesung relevante Material finden in den untenstehenden Links.
Vorlesungsübersicht:
| Woche | Datum | Besprochene Konzepte | Literatur |
|---|---|---|---|
| W1 | 12. Oktober 2010 | Was ist Statistik: Lernen aus Daten, Entwicklung der Statistik im 20 Jahrhundert. Zufallsvariablen: Zufallsvariable, Beobachtungen, Dichtefunktion, Verteilungsfunktion, Erwartungswert, Varianz, Median, Quantilfunktion, Kovarianz, Korrelation. | Kap. 2 in "Statistical Thinking" |
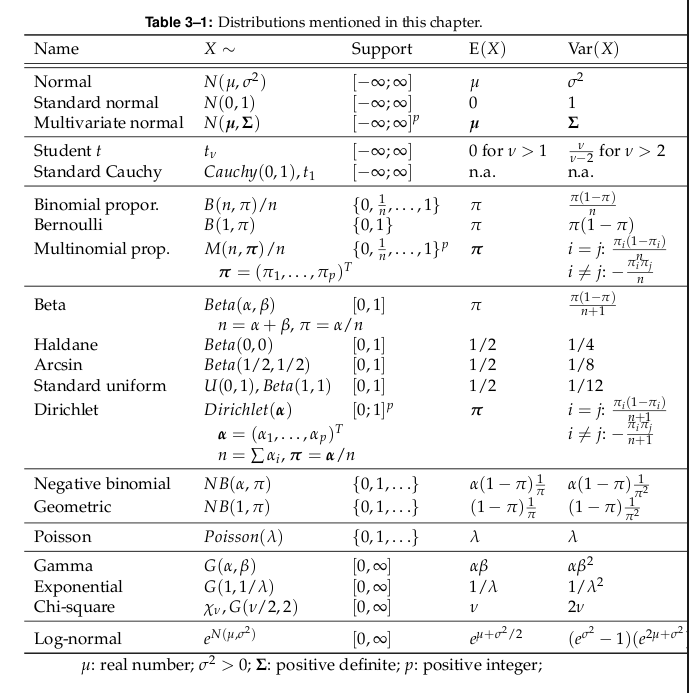
| W2 | 19. Oktober 2010 | Zufallsvariablen II: Identitäten für Erwartungswert und (Ko)varianz, Unabhängigkeit, Variablentransformation, Delta Methode, Jensen Ungleichung. Verteilungen: Normalverteilung, Multivariate Normalverteilung, Exponentialverteilung, Gammaverteilung, Binomialverteilung, Poissonverteilung, Lokationsparameter, Skalenparameter, Varianzstabilisierung. | Katalog wichtiger Verteilungen |
| W3 | 26. Oktober 2010 | Information: Kullback-Leibler Divergenz, Boltzmann Entropie, Shannon Entropie, Mutual Information, Mutual Information zwischen normalverteilten Variablen, Fisher Informationsmatrix | Kap. 4 in "Statistical Thinking" |
| W4 | 2. November 2010 | Explorative Datenanalyse: empirische CDF, Histogramm, Box-Plot, Violin Plot Scatter-Plot, qq-Plot, Ausreißer Inferenz: Statistisches Lernen, Probabilistische Modellierung von Daten, Unsicherheitverteilung Parameter, Schätzfunktion, Eigenschaften von Schätzern, Bias, MSE, Varianz-Bias Zerlegung, Effizienz, Konsistenz, Stichprobenverteilung, Hierarchie Inferenzmethoden: KL, Maximum likelihood, Kleinste Quadrate, Penalized ML, Bayes, empirisches Bayes. Einfache Schätzer: empirischer Erwartungswert, empirische Varianz, ECDF und Histogramm als Schätzer. | |
| W5 | 9. November 2010 | Likelihood Inferenz: Kullback-Leibler Distanz, Approximation grosse Stichprobeb, Maximum-Likelihood, Least-Squares, Likelihood Funktion, Score Funktion, (beobachtete) Fisher Information, Mittelwert als MLE, quadratische Approximation, Likelihood interval, Wald interval, Likelihood ratio, Transformationsinvarianz, Optimalität für große Stichproben, Bias. Cramer-Rao Ungleichung, Overfitting, Suffizienz. | Kap. 7 in "Statistical Thinking" |
| W6 | 16. November 2010 | Regularisierung und Shrinkage: Entscheidungstheorie, Risko, Verlustfunktion,
Hochdimensionale Inferenz, "small n, large p" Daten (z.B. DNA Chips, Proteomics),
Stein-Paradox,
James-Stein Schätzer, Dominanz, Zulässigkeit, Shrinkage, Model Averaging, Bias-Varianz Trade-off,
Regularisierung, hierarchische Modelle, empirische Bayes Inferenz, Shrinkage Schätzer für Varianz und
Korrelation. Entscheidungstheorie, Bayes Risko.
Computerdemonstration:
|
Efron and Morris 1977 - Stein's paradox in statistics. Scientific American 236:119-127. |
| W7 | 23. November 2010 | enfällt | |
| W8 | 30. November 2010 | Frequentistische Fehlerabschätzung: Delta Methode (univariat und multivariat), Standardkonfidenzintervalle, Bootstrapverfahren, Bootstrap-Schätzer für Varianz und Bias, Bootstrap-Schätzer für Konfidenzintervall, Bagging, Jacknife, Prädiktionsfehler, Schätzung duch Kreuzvalidierung. Computerdemonstration: Alle Beispiele benutzen R: | Efron and Gong 1983 - A leisurely look at the bootstrap, the jackknife, and cross-validation. American Statistician 37:36-48. |
| W9 | 7. Dezember 2010 | Bayesianische Inferenz und Sampling Strategien: Bayes' Theorem, A Priori Verteilung, A Posteriori Verteilung, Kredibilitätsintervall, Unterschied zu klassischer Statistik (zufällige Parameter), Bayesian Learning, Zusammenhang mit Shrinkage (Linearität in Exponentialfamilie, Regularisierung), Wahl der Priori, Kompatibilität Priori VT und Likelihood, Jeffreys prior, Referenz Prior, Posteriori Matching Priors. Rejection Sampling, Importance Sampling, Markov Chain Monte Carlo (MCMC), Metropolis Algorithmus, Metropolis Hastings, Gibbs Sampling, Reversible Jump MCMC, Hamiltonian MCMC. Computerdemonstration: Alle Beispiele benutzen R: | Mackay Kap. 29 (Monte Carlo Methods) und Kap. 30 (Efficient Monte Carlo Methods). |
| W10 | 14. Dezember 2010 | Statistisches Testen und Modellwahl: Nullmodell, Alternativverteilung, Mischmodell, Wahl des Schwellenwertes, Fisher's p-Werte (nur Nullmodell), Bayesianische Entscheidungsregel (Nullmodell plus Alternative), Sensitivität, Spezifizität, Power, Recall, False Discovery Rate, False Nondiscovery Rate, True Discovery Rate, Precision, multiples Testen. | PAM und
RDA papers, overview of FDR methods. |
| Frohe Weihnachten und eine guten Rutsch ins Jahr 2011! | |||
| W11 | 4. Januar 2011 | Klassifikationsverfahren: Prädiktionsproblem, Mischmodell, Diskriminanzfunktion, Entscheidungsgrenzen, Zentroide, gemeinsame oder getrennte Kovarianzmatrizen, Quadratische Diskriminanzanalyse (QDA), Lineare Diskriminanzanalyse (LDA), Diagonale Diskriminanzanalyse (DDA), weitere Verfahren (SVM, Naive Bayes, logistische Regression), Variablenselection, LDA für zwei Klassen, t-Statistik. Regularisierte Diskriminanzanalyse, PAM (Tibshirani), RDA (Hastie). Computerdemonstration: Alle Beispiele benutzen R: | Hastie et al., Kap. 4. |
| W12 | 11. Januar 2011 | Regression: Lineares Modell, Prediktoren, Response, Regressionskoeffizienten, Residual, RSS, Normalengleichung, Least-Squares Schätzer, ML Schätzer, Zusammenhang Regressionskoeffizient und partieller Korrelation und partieller Varianz, generalisierte lineares Modell (GLM), Link Funktion, Exponentialfamilie, logistische Regression und Logit Link, generalisiertes additives Modell (GAM), Ridge Regression, Lasso Regression, L1 und L2 Penalisierung, Dantzig Selector, LARS, Elastic Net, Variablenselektion. | Hastie et al. (Kapitel 3) |
| W13 | 18. Januar 2011 | Zeitreihenanalyse: Zeitreihe, longitudinale Daten, Trend, Autocovarianz, Autokorrelation, Stationarität, Variogramm, Korrelogramm, Periodogramm, Spektrum, Schätzung der Autocorrelation, AR Modell, VAR Modell, State-Space Modell, ARMA, GARCH. | Diggle (Kapitel 1 bis 3) |
| W14 | 25. Januar 2011 |
Räumliche Statistik:
Räumliche Daten, räumliches Modellieren, räumliche Kovarianzfunktion,
geostatistische Modell, Stationarität, Istropie, Gauss-Modell, räumliches GLM,
räumliches Variogramm, Matern Kovarianzfunktion, räumliche Prädiktion,
Kriging. Computerdemonstration: |
Diggle und Ribeiro Jr. (Kapitel 1-3) |
| W15 | 1. Februar 2011 | Prüfungen |
{kind=link}